Scale Without Sacrifice: Automating Complexity in the Era of AI Content
In the world of digital marketing, “Programmatic SEO” has become a dirty word.
For most people, it conjures images of thousands of low-quality, cookie-cutter pages that offer zero value—the kind of “spam” that search engines are aggressively de-indexing. The assumption is simple: you can have Quality, or you can have Scale, but you cannot have both.
At Nexus Websites, we reject that binary. We believe the problem isn’t automation itself; the problem is what people are automating.
Most agencies use AI to generate text blobs. They ask ChatGPT to “write a product description,” paste the result into a WordPress text editor, and call it a day. This works for simple blogs, but it fails spectacularly for complex, data-driven websites—e-commerce stores, industrial catalogs, and technical service portfolios.
We built our own engine—the PPG (Product Page Generator) Protocol—to solve a specific engineering challenge: How do you automate the creation of high-fidelity, database-structured content that retains the complexity of a hand-coded page?
This is how we achieve scale without sacrificing the intricate data structures that drive modern SEO.

The “Text Blob” Problem
To understand our solution, you have to understand how WordPress and modern CMSs actually work.
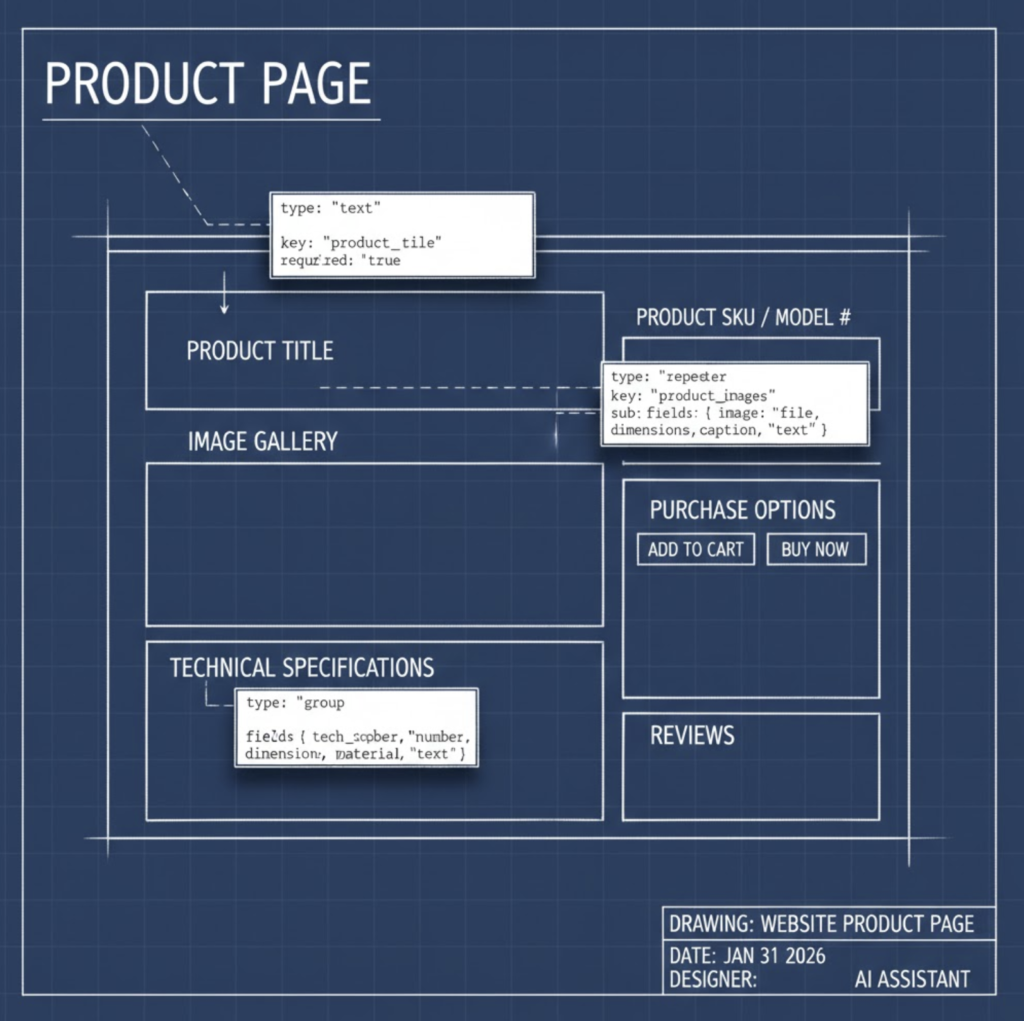
A high-quality product page is rarely just a single block of text. It is a collection of specific data points stored in separate database fields.
- Price: Stored as a number.
- SKU: Stored as a string.
- Specifications: Stored as a “Repeater” (a loop of rows and columns).
- Gallery: Stored as an array of Image IDs.
Standard AI tools are terrible at this. If you give an AI a PDF and say “write a page,” it returns a wall of text. It might mention the price inside a paragraph, but it doesn’t know how to put that price into the _regular_price field in your database.
This results in “flat” pages. They look okay to a human reading them, but to the website’s search bar, filter system, and schema generator, they are invisible. You can’t filter by “Weight” if the weight is buried in a paragraph of prose.
The Blueprint Architecture: Engineering Before Writing
We don’t start with writing. We start with architecture.
Our proprietary tool uses a “Blueprint” method. Before the AI generates a single word, our system scans the Advanced Custom Fields (ACF) structure of the client’s website. It reads the underlying JSON schema of the database to understand exactly what fields exist, what data types they expect, and how they relate to each other.
It essentially creates a rigid skeleton for the content. It knows that specifications is not a text box, but a Repeater field requiring an array of objects, each containing a label and a value.
Handling the “Repeater” Complexity
The hardest thing to automate in WordPress is nested data—specifically, Repeater Fields and Flexible Content. These are the tools developers use to build complex tables, accordions, and tabbed content.
Most AI importers break when they hit a Repeater. They try to shove all the data into one cell.
Our engine is instructed to act as a JSON Architect. When it encounters a technical specification in a source PDF—say, a table listing engine torque across five different RPMs—it doesn’t summarize it. It parses it into a strict array of objects.
This allows us to take a static PDF brochure and transmute it into a dynamic, filterable data table on the website. The user sees a beautiful table; the database sees structured rows. This is the difference between a “blog post about a product” and a true “Product Page.”
The “Source of Truth” Extraction Layer
Where does the data come from?
Hallucination is the enemy of SEO. If an AI invents a feature that doesn’t exist, it creates a customer service nightmare. To prevent this, we utilize a “Source of Truth” methodology.
We don’t let the AI browse the open web. Instead, we feed it specific, manufacturer-provided PDF documents. We built a browser-native extraction layer that utilizes PDF.js to scrape raw text directly from technical manuals and brochures.
This creates a closed loop. The AI is only allowed to generate content based on the “Dump” we provide. If the PDF says the machine weighs 400kg, the website says 400kg.
The Taxonomy Intelligence
Content is useless if it lands in the wrong category.
Imagine uploading 500 products. Manually ticking the “Category” boxes for each one would take hours. Standard importers make you define this in a spreadsheet beforehand.
Our system uses Taxonomy Intelligence. It analyzes the semantic content of the source text and compares it against the existing category structure of the website.
- It reads the text: “Ideal for heavy-duty forestry work…”
- It checks the database: Finds specific term IDs for the “Forestry” category and the “Heavy Duty” tag.
- It maps them automatically.
This ensures that even when we automate the creation of hundreds of pages, the site architecture remains clean, organized, and navigable.
The “Sanitization” Protocol
One of the hidden risks of AI database injection is “Type Mismatch.”
If your database expects an Integer (e.g., 1 or 0 for “In Stock”) and the AI returns a String (e.g., “Yes” or “True”), it can break the frontend display.
Our engine includes a dedicated Sanitization Layer. After the AI generates the draft, but before it saves to the database, our code runs a deep clean:
- Type Enforcement: It forces “True/False” values into the
1/0format WordPress prefers. - Image Logic: It converts image URLs back into their specific Attachment IDs so the media library stays synced.
- Null Handling: It catches “null” strings that AI sometimes outputs and converts them to actual empty values to prevent database clutter.
The Human-in-the-Loop Dashboard
Finally, we believe in “Augmentation,” not “replacement.”
Complete automation is dangerous. You need a pilot in the cockpit. We built a custom interface inside the WordPress backend that allows our editors to manage the chain of events.
Before the “Finalize” button is clicked, our team can map specific assets. They can select a Featured Image or a Gallery of assets from the media library, and the system creates a “Media Context” map. The AI then places these specific image IDs into the correct slots in the content layout.
This hybrid approach gives us the speed of AI with the visual precision of a human designer.
Conclusion: Complexity is the New Moat
Anyone can spin up a thousand blog posts today. That is no longer a competitive advantage; it’s a commodity.
The new “Moat” in SEO is Complexity.
Search engines and LLMs are hungry for structured, validated data. They want to know exactly how much a product weighs, exactly what its dimensions are, and exactly which category it belongs to.
By automating the complexity—by treating content as data rather than just words—Nexus Websites builds digital infrastructure that stands up to scrutiny. We don’t just fill pages; we populate databases. And in the age of AI search, the database wins.
